Authors:
David WeinbergerPublished:
This project comes from an amateur, not from the excellent devs here at the Lab. I’m a co-director, not a developer. If you look at the code (github) you will have a good laugh. On the other hand, the fact that someone at my level of “skill” can create a semi-workable piece of code is a testament to LibraryCloud’s usability. (Also to Paul Deschner’s patience with my questions. Thanks, Paul.)
Harvard Library has 13M items in its collection. Harvard is digitizing many of them, but as of now you cannot do a full text search of them.
Google Books had 30M books digitized as of a year ago. You can do full-text searches of them.
So, I wrote a little mash-up app that lets you search Google Books for text, and then matches up the results with books in Harvard Library. It’s a proof of concept, and I’m counting the concept as proved, or at least as promising. On the other hand, my API key for Google Books only allows 2,000 queries a day, so it’s not practical on the licensing front.
This project runs on top of LibraryCloud. LibraryCloud provides an API to Harvard’s open library metadata and more. (We’re building a new, more scalable version now. It is, well, super-cool.)
Some details below the clickable screenshot…
Click on the image to expand it.
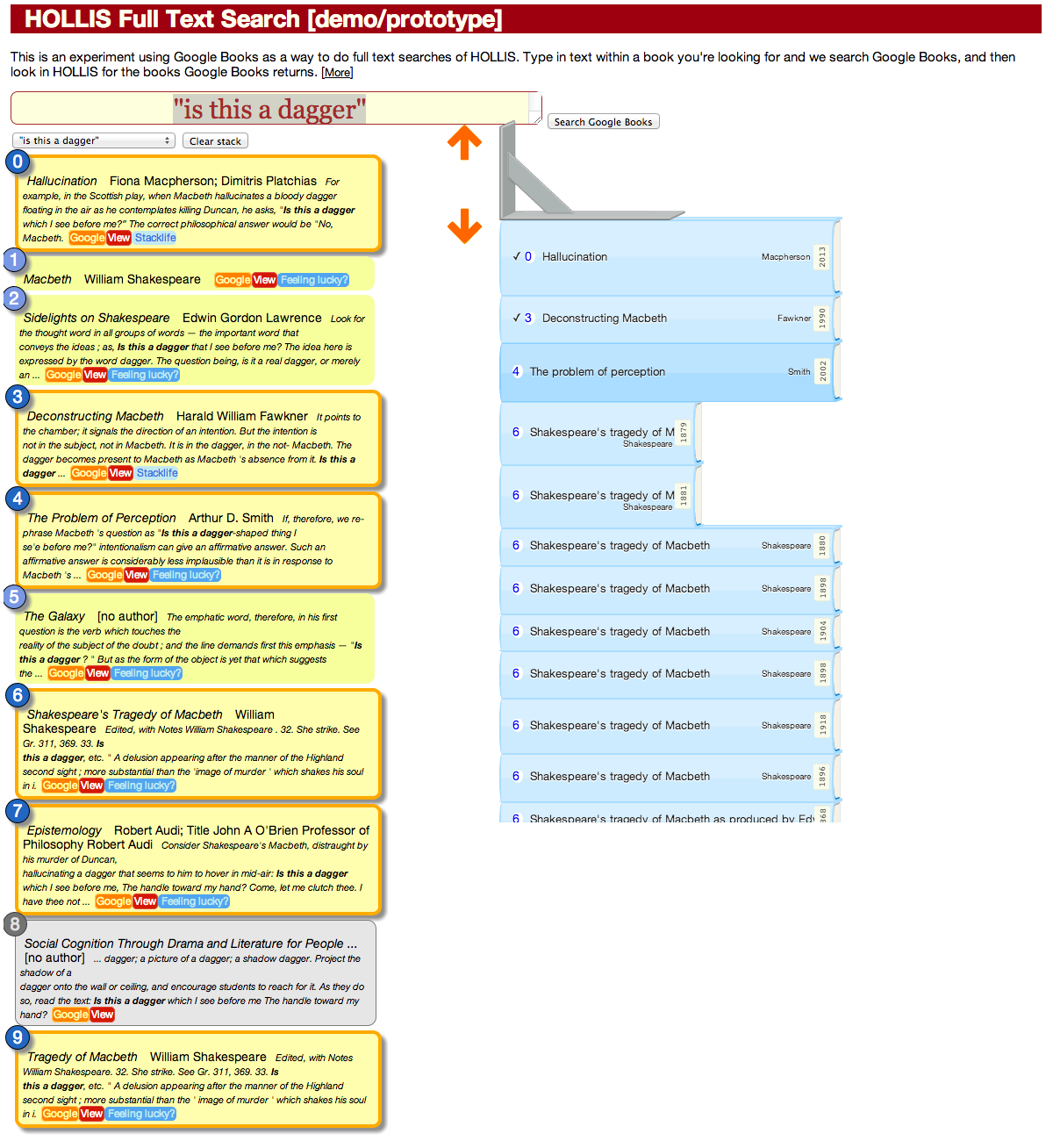
The Google Books results are on the left (only ten for now), and HOLLIS on the right.
If a Google result is yellow, there’s a match with a book in HOLLIS. Gray means no match. HOLLIS book titles are prefaced by a number that refers to the Google results number. Clicking on the Google results number (in the circle) hides or shows those works in the stack on the right; this is because some Google books match lots of items in HOLLIS. (Harvard has a lot of copies of King Lear, for example.)
There are two types of matches. If an item matched on a firm identifier (ISBN,OCLC, LCCN), then there’s a checkmark before the title in the HOLLIS stack, and there’s a “Stacklife” button in the Google list. Clicking on the Stacklife button displays the book in Harvard StackLife, a very cool—and prize winning!—library browser created by our Lab. The StackLife stack colorizes items based on how much they’re used by the Harvard community. The thickness of the book indicates its page count and its length indicates its actual physical height.
If there’s no match on the identifiers, then the page looks for a keyword match on the title and an exact match on the author’s last name. This can result in multiple results, not all of which may be right. So, on the Google result there’s a “Feeling lucky” button that will take you to the first match’s entry in StackLife.
The “Google” button takes you to that item’s page at Google Books, filtered by your search terms for your full-texting convenience.
The “View” button pops up the Google Books viewer for that book, if it’s available.
The “Clear stack” button deselects all the items in the Google results, hiding all the items in the HOLLIS stack.
Let me know how this breaks or sucks, but don’t expect it ever to be a robust piece of software. Remember its source.