Published:
This guest post is part of the CAP Research Community Series. This series highlights research, applications, and projects created with Caselaw Access Project data.
Abdul Abdulrahim is a graduate student at the University of Oxford completing a DPhil in Computer Science. His primary interests are in the use of technology in government and law and developing neural-symbolic models that mitigate the issues around interpretability and explainability in AI. Prior to the DPhil, he worked as an advisor to the UK Parliament and a lawyer at Linklaters LLP.
The United States of America (U.S.) has seen declining public support for major political institutions, and a general disengagement with the processes or outcomes of the branches of government. According to Pew’s Public Trust in Government survey earlier this year, “public trust in the government remains near historic lows,” with only 14% of Americans stating that they can trust the government to do “what is right” most of the time. We believed this falling support could affect the relationship between the branches of government and the independence they might have.
One indication of this was a study on congressional law-making which found that Congress was more than twice as likely to overturn a Supreme Court decision when public support for the Court is at its lowest compared to its highest level (Nelson & Uribe-McGuire, 2017). Furthermore, another study found that it was more common for Congress to legislate against Supreme Court rulings that ignored the legislative intentions, or rejects positions taken by federal, state, or local governments — due to ideological differences (Eskridge Jr, 1991).
To better understand how the interplay between the U.S. Congress and Supreme Court has evolved over time, we developed a method for tracking the ideological changes in each branch using word embeddings and text corpora generated. For Supreme Court, we used the opinions for the cases provided in the CAP dataset — though we extended this to include other federal court opinion to ensure our results were stable. As for Congress, we used the transcribed speeches of the Congress from Stanford’s Social Science Data Collection (SSDS) (Gentzkow & Taddy, 2018). We use the case study of reproductive rights (particularly, the target word “abortion”), which is arguably one of the more contentious topics ideologically divided Americans have struggled to agree on. Over the decades, we have seen shifts in the interpretation of rights by both the U.S. Congress and Supreme Court that has arguably led to the expansion of reproductive rights in the 1960s and a contraction in the subsequent decades.
What are word embeddings? To track these changes, we use a quantitative method of tracking semantic shift from computational linguistics, which is based on the co-occurrence statistics of words used — and corpora of Congress speeches and the Court’s judicial opinions. These are also known as word embeddings. They are a distributed representation for text that is perhaps one of the key breakthroughs for the impressive performance of deep learning methods on challenging natural language processing problems. This allows us to see, using the text corpus as a proxy, how they have ideologically leaned over the years on the issue of abortion, and whether any particular case led to an ideological divide or alignment.
For a more detailed account on word embeddings and the different algorithms used, I highly recommend Sebastian Ruder’s “On word embeddings”.
Our experimental setup In tracking the semantic shifts, we evaluated a couple of approaches using a word2vec algorithm. Conceptually, we formulate the task of discovering semantic shifts as follows. Given a time sorted corpus: corpus 1, corpus 2, …, corpus n, we locate our target word and its meanings in the different time periods. We chose the word2vec algorithm based comparisons made on the performance of the different algorithms which were count-based, prediction-based or a hybrid of the two on a corpus of U.S. Supreme Court opinions. We found that although there is variability in coherence and stability as a result of the algorithm chosen, the word2vec models show the most promise in capturing the wider interpretation of our target word. Between the two word2vec algorithms — Continuous Bag of Words (CBOW) and Skip-Gram Negative Sampling (SGNS) — we observe similar performance, however, the latter showed more promising results in capturing case law related to our target word at a specific time period.
As we test one algorithm in our experiments — a low dimensional representation learned with SGNS — with the incremental updates method (IN) and diachronic alignment method (AL), we got results for two models SGNS (IN) and SGNS (AL). In our implementation, we use parts of the Python library gensim and supplement this with implementations by Dubossarsky et al. (2019) and Hamilton et al. (2016b) for tracking semantic shifts. For the SGNS (AL) model, we only extract regular word-context pairs (w,c) for time slices and trained SGNS on these. For the SGNS (IN) model, we similarly extract the regular word-context pairs (w,c), but rather than divide the corpus and train on separate time bins, we train the first time period and incrementally add new words, update and save the model.
To tune our algorithm, we performed two main evaluations (intrinsic and extrinsic) on samples of our corpora, comparing the performance across different hyperparameters (window size and minimum word frequency). Based on these results, the parameters used were MIN = 200 (minimum word frequency), WIN = 5 (symmetric window cut-off), DIM = 300 (vector dimensionality), CDS = 0:75 (context distribution smoothing), K = 5 (number of negative samples) and EP = 1 (number of training epochs).
What trends did we observe in our results? We observed some notable trends from the changes in the nearest neighbours to our target word. Using the nearest neighbours to abortion indicates how the speakers or writers who generated our corpous associate the word and what connotations it might have in the group.
To better assess our results, we conducted an expert interview with a Womens and Equalities Specialist to categorise the words as: (i) a medically descriptive word, i.e., it relates to common medical terminology on the topic; (ii) a legally descriptive word, i.e., it relates to case, legislation or opinion terminology; and (iii) a potentially biased word, i.e., it is not a legal or medical term and thus was chosen by the user as a descriptor.
Nearest Neighbours Table Key. Description of keys used to classify words in the nearest neighbours by type of terminology. These were based on the insights derived from an expert interview.
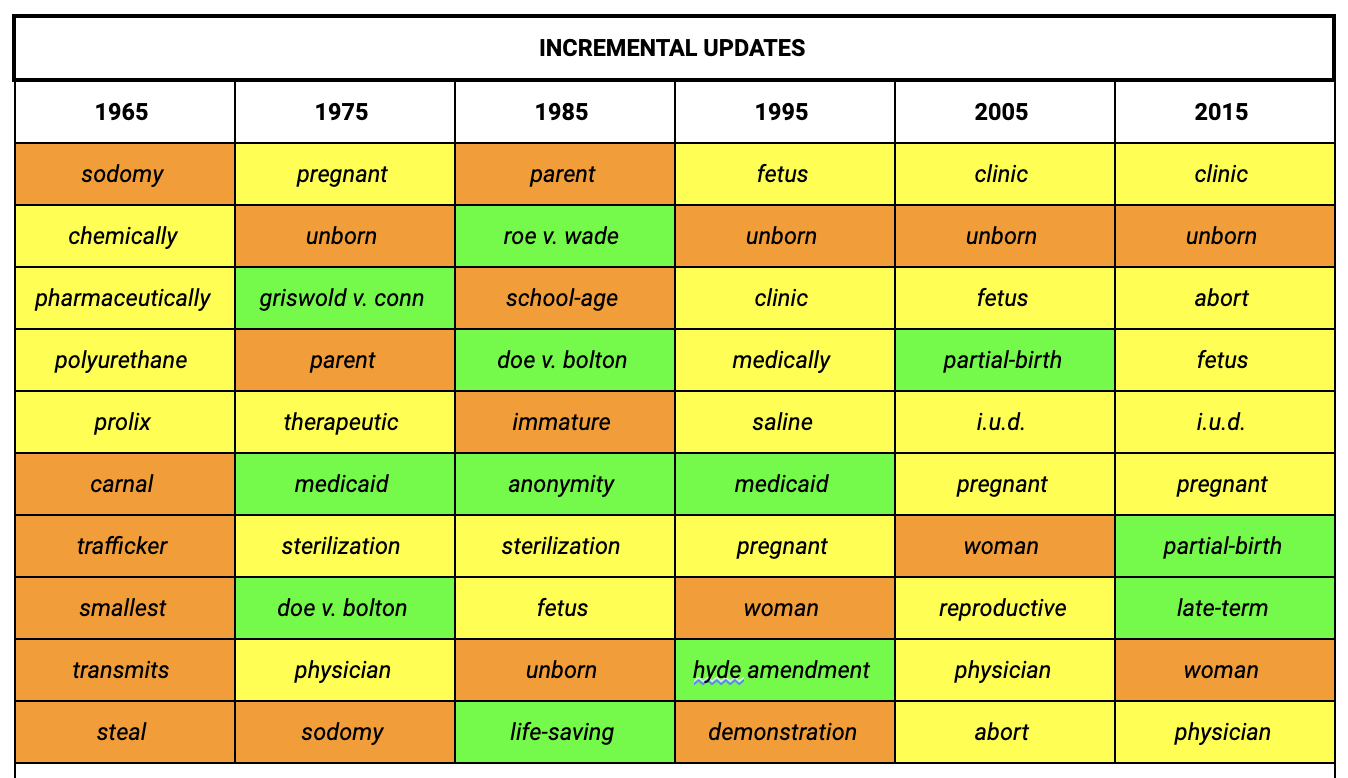
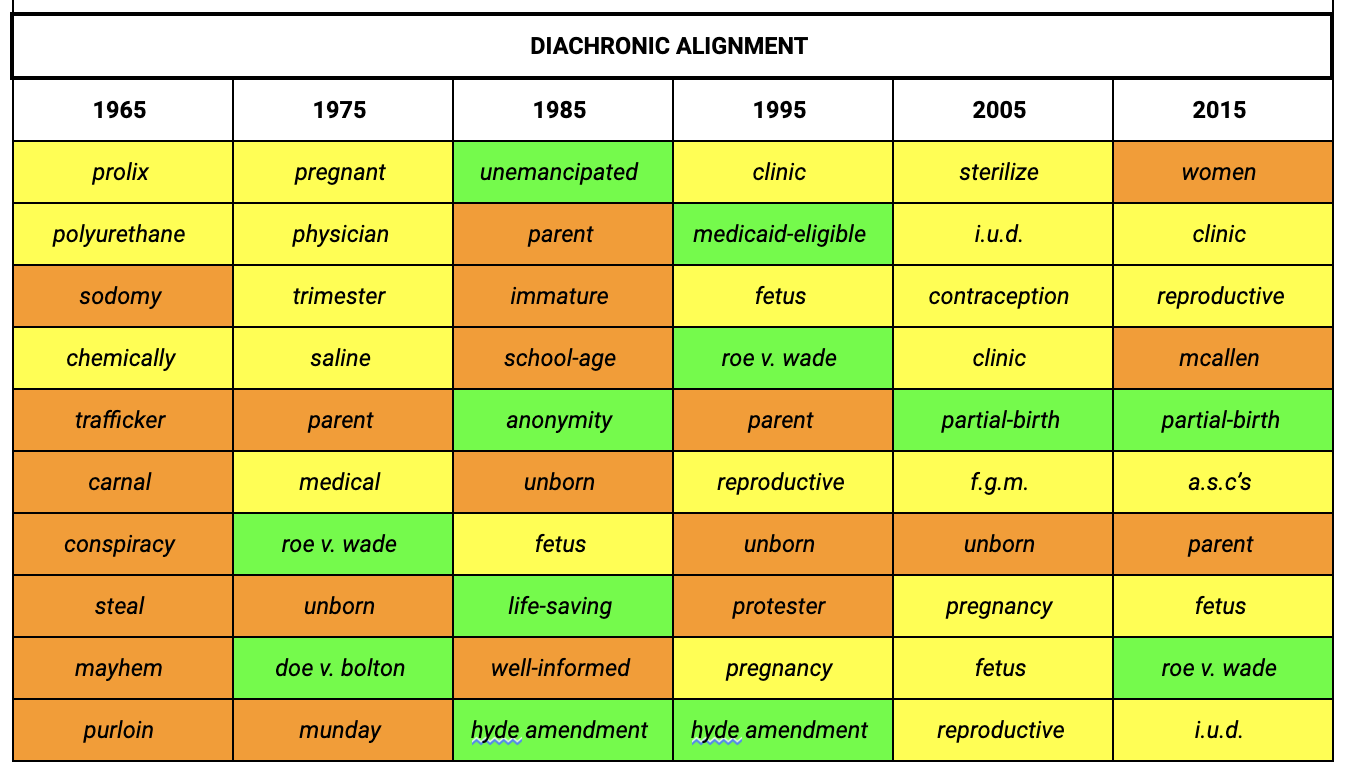
A key observation we made on the approaches to tracking semantic shifts is that depending on what type of cultural shift we intend to track, we might want to pick a different method. The incremental updates approach helps identify how parts of a word sense from a preceding time periods change in response to cultural developments in the new time period. For example, we see how the relevance of Roe v. Wade (1973) changes across all time periods in our incremental updates model for the judicial opinions.
In contrast, the diachronic alignment approach better reflects what the issues of that specific period are in the top nearest neighbours. For instance, the case of Roe v. Wade (1973) appears in the nearest neighbours for the judicial opinions shortly after it is decided in the decade up to 1975 but drops off our top words until the decades up to 1995 and 2015, where the cases of Webster v. Reproductive Health Services (1989), Planned Parenthood v. Casey (1992) and Gonzales v. Carhart (2007) overrule aspects of Roe v. Wade (1973) — hence, the new references to it. This is useful for detecting the key issues of a specific time period and explains why it has the highest overall detection performance of all our approaches.
Local Changes in U.S. Federal Court Opinions. The top 10 nearest neighbours to the target word “abortion” ranked by cosine similarity for each model.
Local Changes in U.S. Congress Speeches. The top 10 nearest neighbours to the target word “abortion” ranked by cosine similarity for each model.
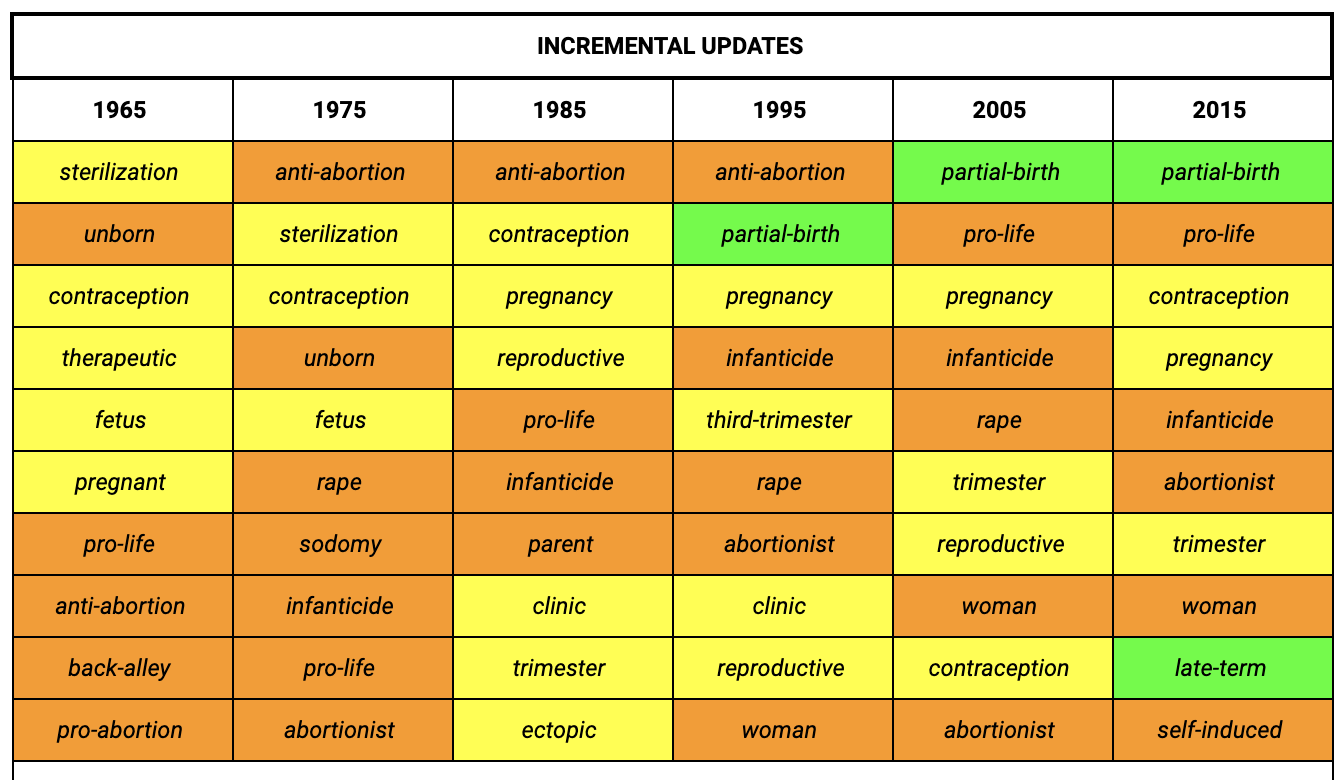
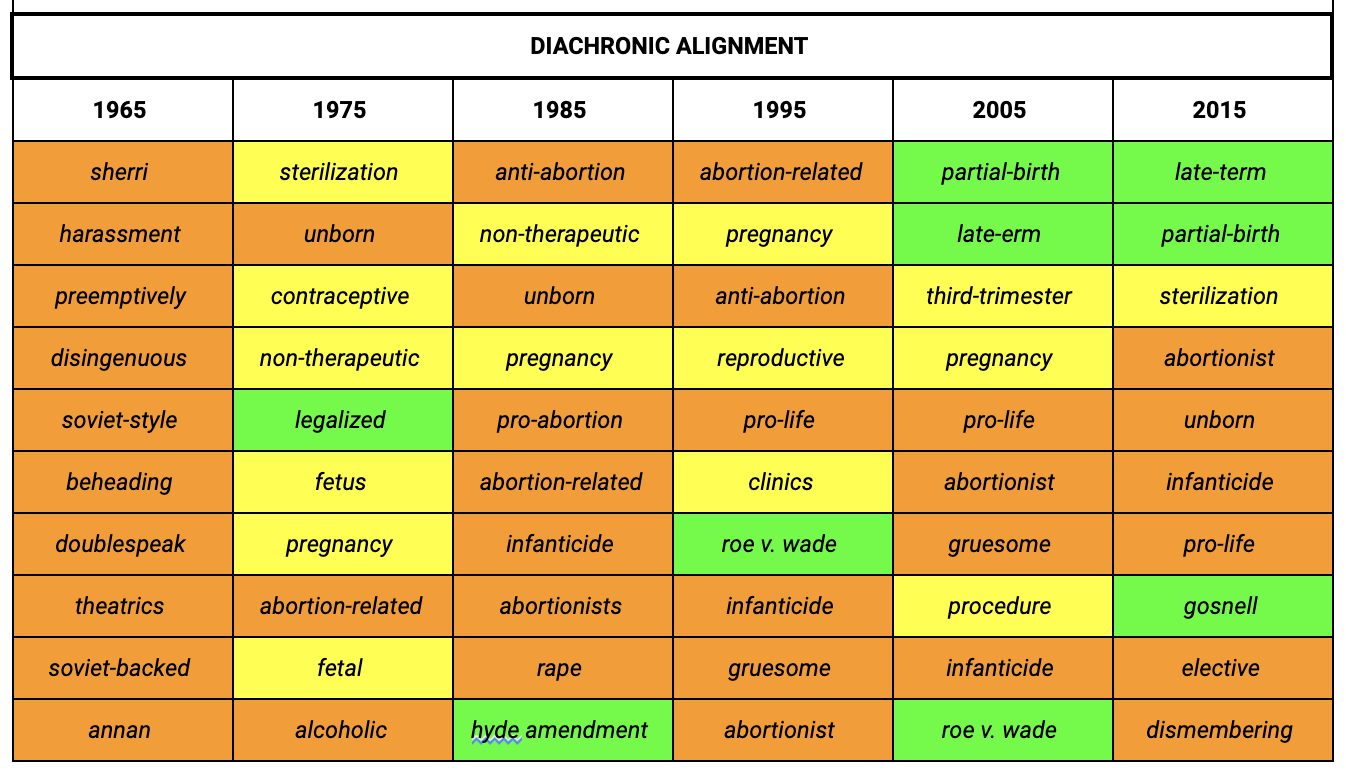
These preliminary insights allow us to understand some of the interplay between the Courts and Congress on the topic of reproductive rights. The method also offers a way to identify bias and how it may feed into the process of lawmaking. As such, for future work, we aim to refine the methods to serve as a guide for operationalising word embeddings models to identify bias - as well as the issues that arise when applied to legal or political corpora.