Authors:
Drew (Andy) SilvaPublished:
Courts and the legal publishers that serve them, by necessity, are creatures of habit. A case's fundamental structure hasn't changed much, whether published early in the 19th century or during the COVID pandemic. Even when publishers started taking their wares online, they didn't stray far from their well-worn model. In many ways, that's a good thing. I imagine legal research and writing would be much more arduous if fundamental case elements were as inconsistent as citation schema over the years.
But we think these cases have undiscovered uses beyond informing legal arguments. We know that NLP (Natural Language Processing) folks have already made use of the API and bulk download tools we built at http://case.law. Still, the most frequently accessed pages on our website are individual case pages from google visitors. What are their needs? Historical research? Family history? .… leisure? Even if the fundamental structure of a case is necessarily immutable, are there opportunities for novel interfaces to bring these works to new audiences?
Process
The first step I took was to assemble a list of actions that people perform on collections of things.

Among these ideas, I was most interested in enhancing people’s ability to cut through the endless walls of text we serve up to find what they’re looking for. This is a more cut-and-dried topic for an interface exploration, so I spent most of my time there.
I am also interested in humanizing the stories behind these cases through narrative. Too often, the technical analysis of these legal documents overshadows that they describe real events in real people’s lives. Not only have the subjects of these cases often endured gruesome, traumatic events, but the trials themselves are often traumatic. While I only lightly touched on this direction here, I’d very much like to explore it in the future.
The Results
Topic Explorer
Topic Explorer is a simple idea based on data or a data interface that does not exist. What if you could find the number of cases that contain a specific word and then get a list of the most frequently used important words in those cases?
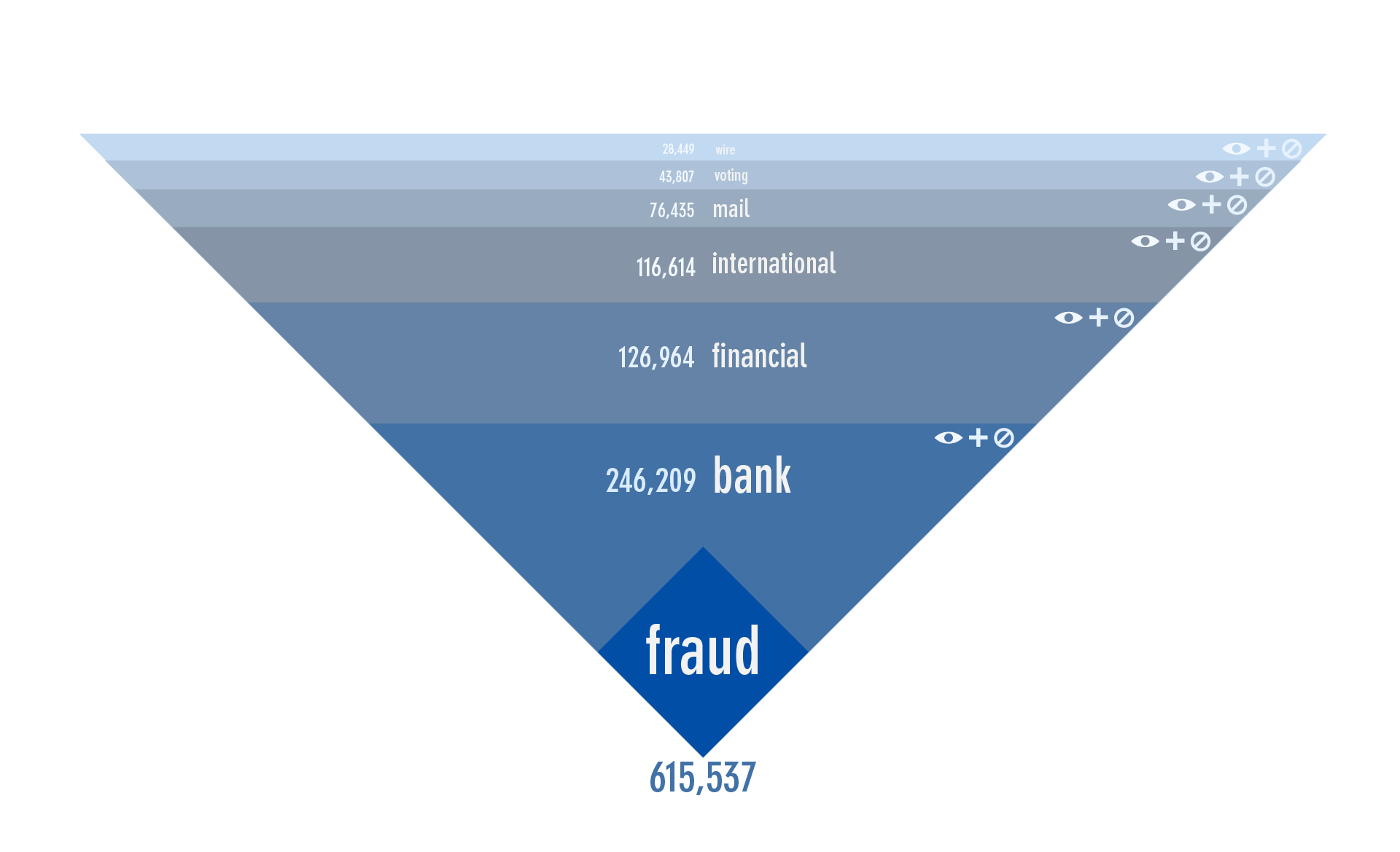
At that point, you could add that word to your search.
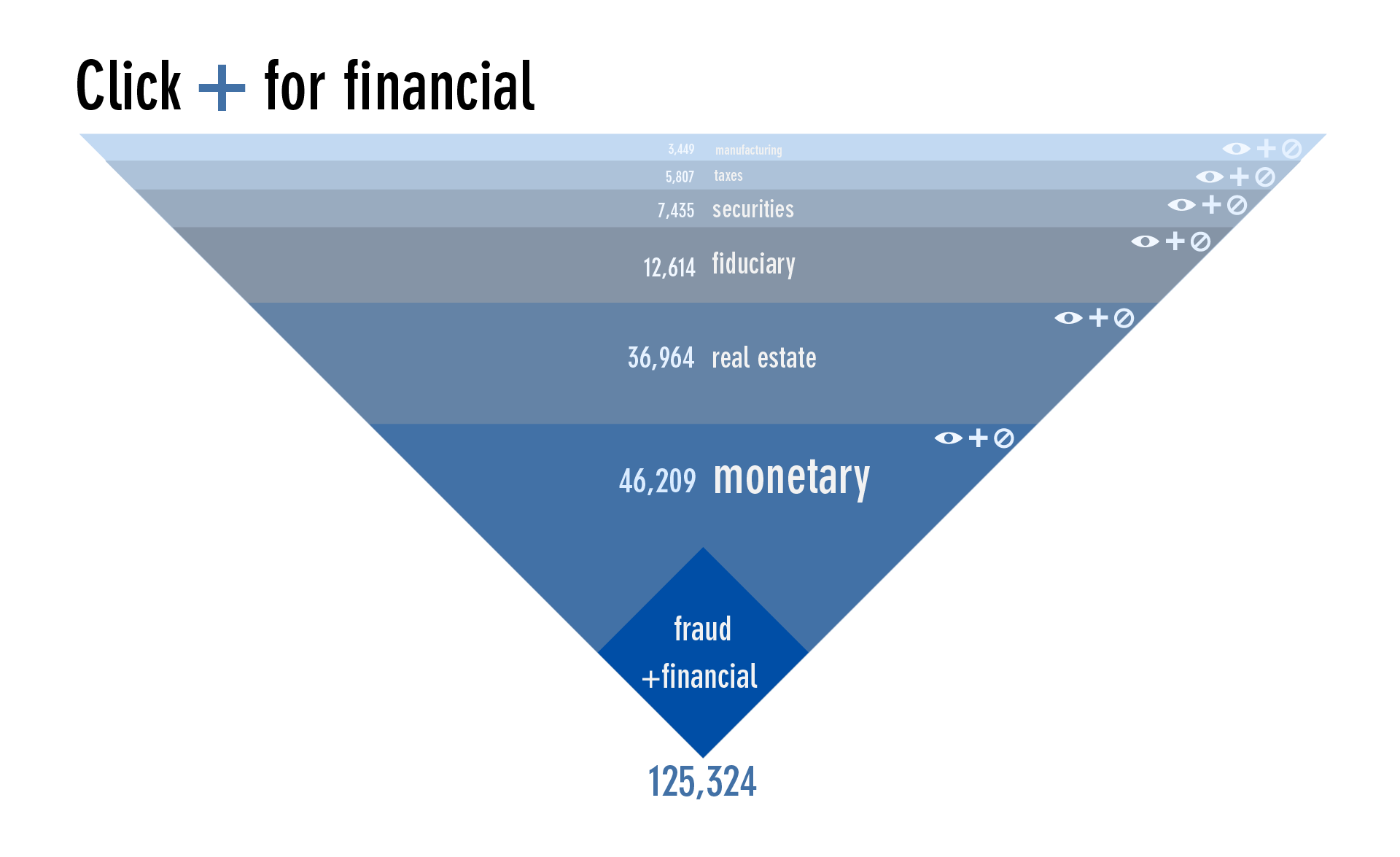
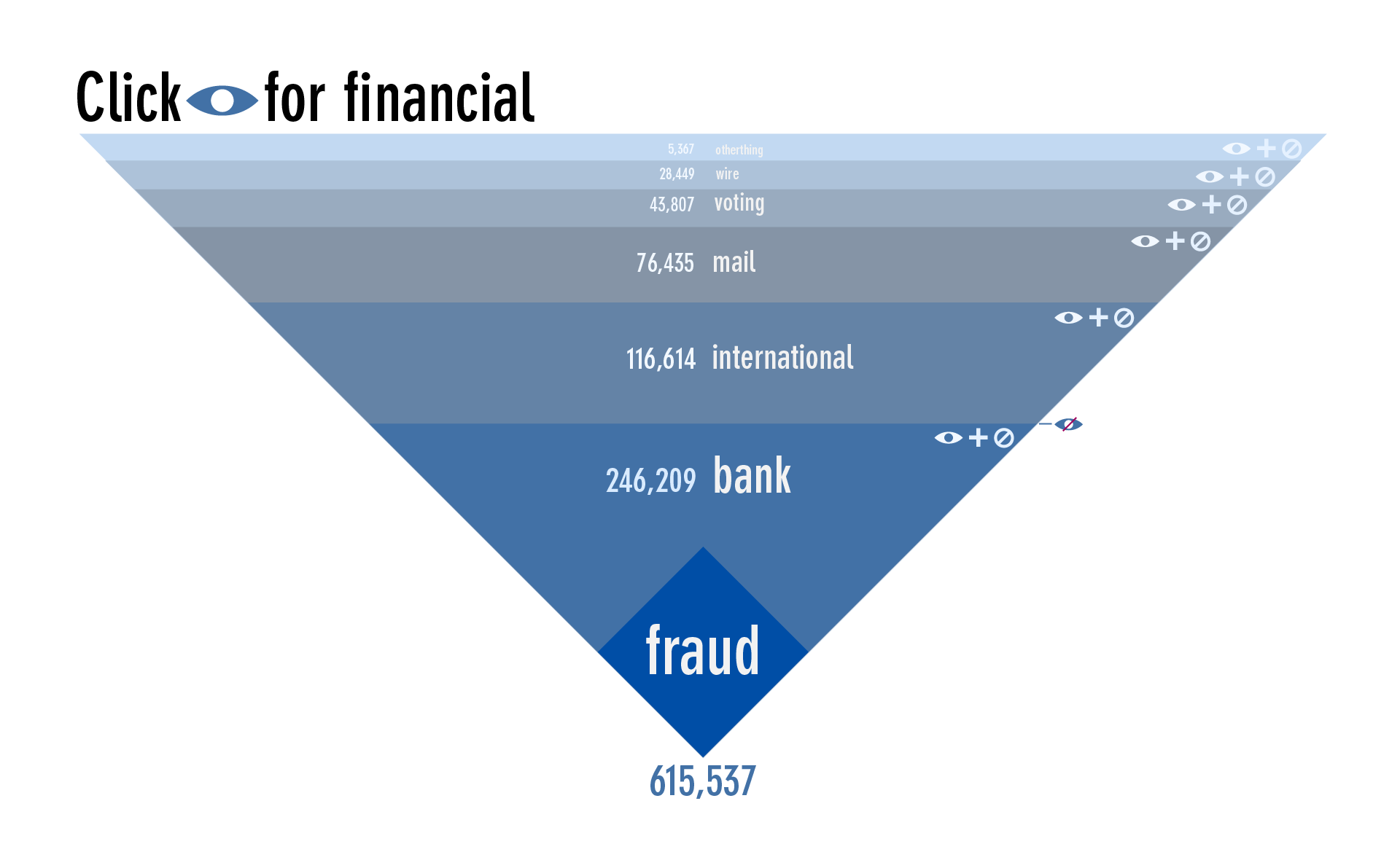
Or hide it to expose more words.
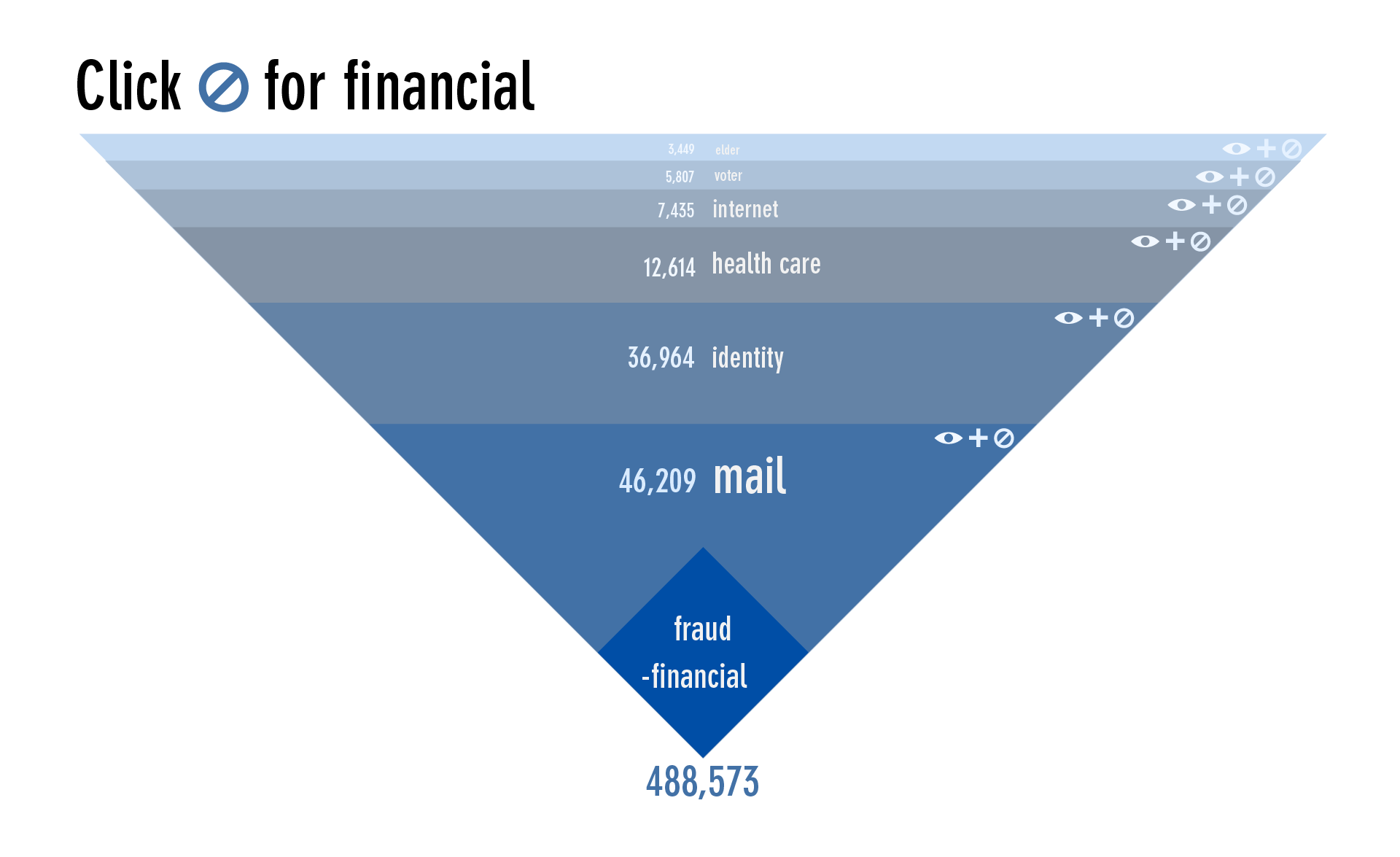
Exclude it from your search to go in a different direction.
Trace Topic
Though based on the same interest in exploring a topic, this approach is a bit different. The idea is that within a case, you could highlight a word and then see how frequently that word appears in cases that cite to the case you're reading and cases that cite to those cases. The idea is that you could drill down from that topic into different usages within related cases.
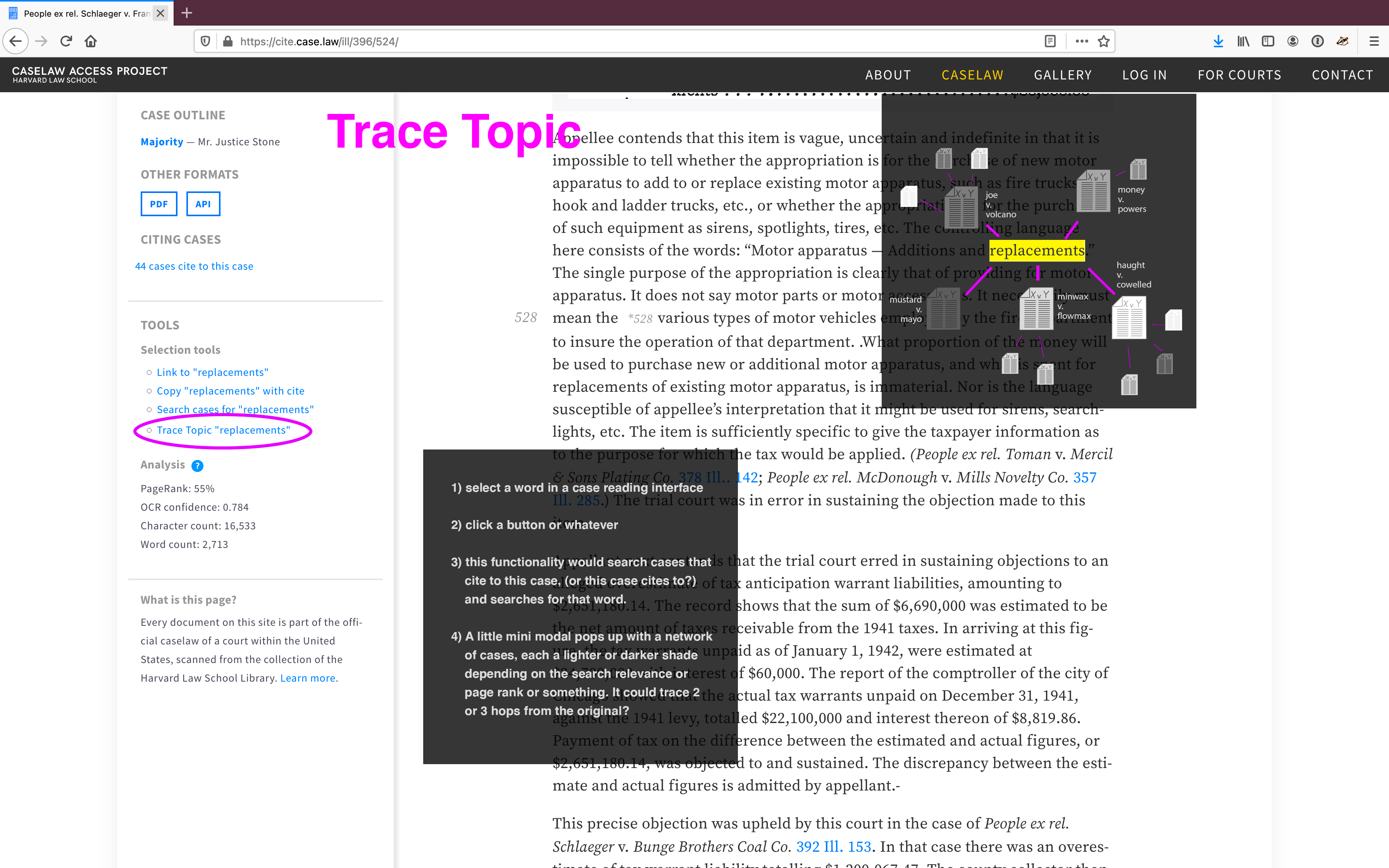
The color of the case represents the relevance of the term in that search, or whatever else you want it to be, really.
Clandestine Conversation
This completely different approach to digging into a specific topic involves trying to facilitate conversation among readers. Maybe someone could annotate a highlighted passage with an invitation to discuss it.
Enter the text:

Users see a symbol:

They click on it and get the invitation:

Ratings and Reviews
Maybe people have feelings about cases best expressed through star ratings and reviews? Frankly, they probably don't, but it seemed like too familiar an idiom to ignore.
Geo Trends
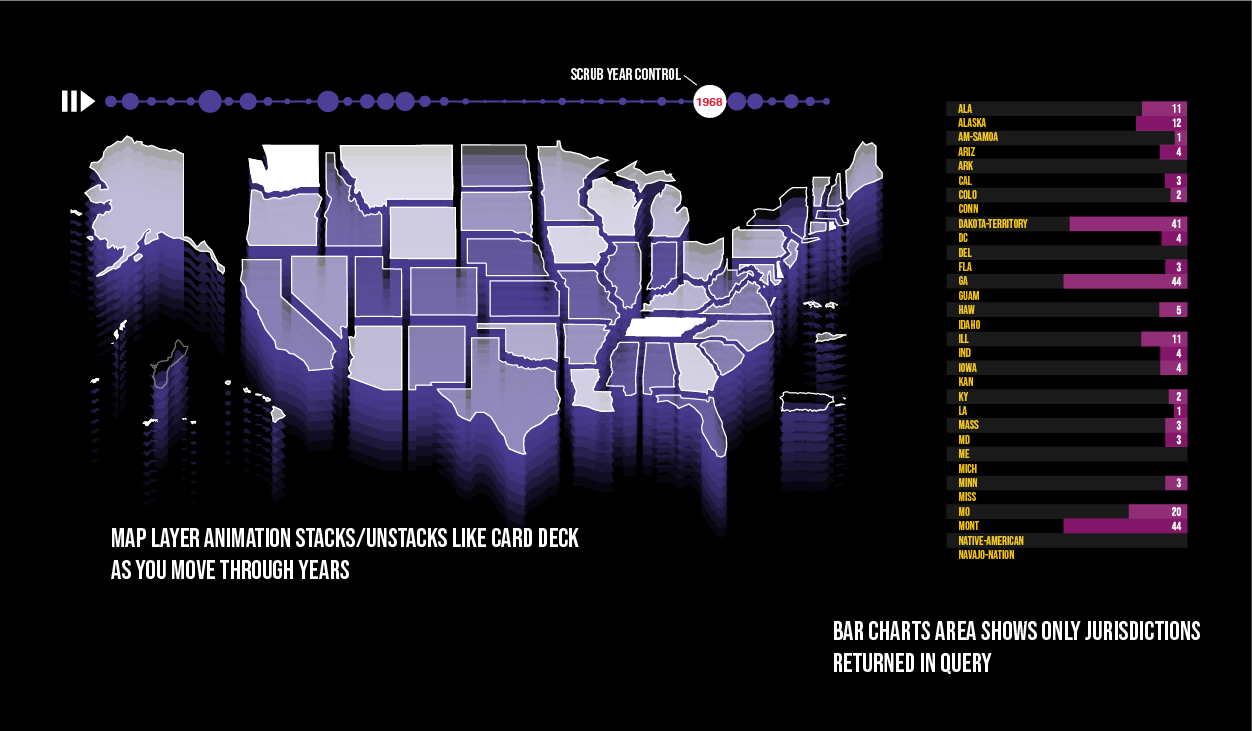
If you haven't had a chance to check out our trends viewer, I highly recommend you drop what you're doing and play for a little while. Like Google's Ngram viewer, it will tell you the frequency with which a word appears in cases over time. You can even split it up by jurisdiction! However, if you want to see how something trends in ALL jurisdictions, it's a little tough to read.
Rather than having all years and jurisdictions visible, I represented jurisdictions on a map and added a year scrubber control. You can get the precise numbers for that year from the list on the right.
3D Timeline Explorer
Our developer Anastasia is working on a very cool legally-focused storytelling interface we call Timeline. Its users can create legally-focused timelines that include cases, important dates and events, and narrative. Inspired by some of the new proximity conferencing tools, such as gather.town, I designed an interface with which someone could explore one of these timelines in a 3D environment.
Users access different bits of media when moving their sprite over different hot spots on the timeline.
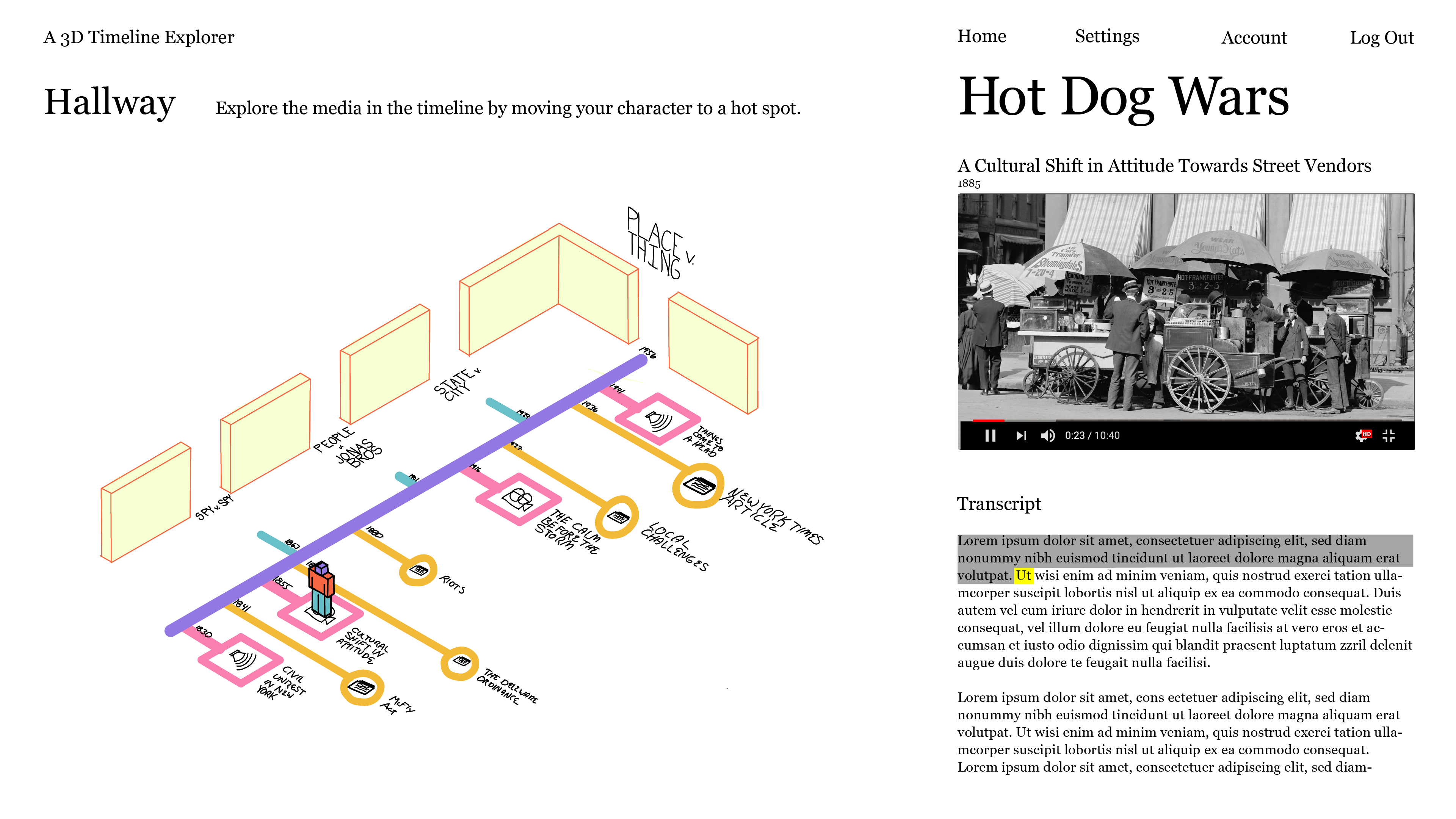
Since we are primarily a caselaw database, court cases would probably get special treatment. Each case could have a virtual courtroom with different hot spots for different participants in the process.

Sound of an Opinion
Like Topic Explorer, Sound of an Opinion would require data we don't yet have. Using pre-made or algorithmically-created sound clips, we would convey the emotional tone and other measurable facets of an opinion based on text sentiment analysis. In my simplistic demo, I correlate positivity/negativity with instrumentation and scale, verb density with the drumline volume, and adjective density with the drumline complexity. The sound clips were created in Logic Pro X using Apple Loops and their algorithmic drum beat creator.

Check out this live ProtoPie demo (that will not work in Safari.)
Next Steps
While few, if any of these ideas will be fully realized, unencumbered, blue-skies thinking is time well spent around here. We've already started investigating the feasibility of generating and serving sentiment analysis data through our API. Do any of these ideas excite you? Do you have any ideas of your own you think belong here? Reach out and let us know!