Authors:
Adam Ziegler and Kelly FitzpatrickPublished:
The Caselaw Access Project offers free, public access to over 6.5 million decisions published by state and federal courts throughout American history. We make these decisions available in a variety of formats through a variety of different access methods.
Court decisions obviously are documents that can be read and interpreted by people, but they’re also data that can be processed and analyzed by machines. We try to reflect this principle by designing interfaces that are useful for people (such as our search interface and case viewer) and for programs (our API).
Connecting Human Interfaces with Machine Interfaces
One of our favorite things is connecting these two types of interfaces together so that people who may be accustomed to searching for and reading cases can also begin to understand the cases as structured data that can be processed by programs. So, for example, our human search interface has a “SHOW API CALL” link that will display and explain the URL that is used by our API to execute your search:
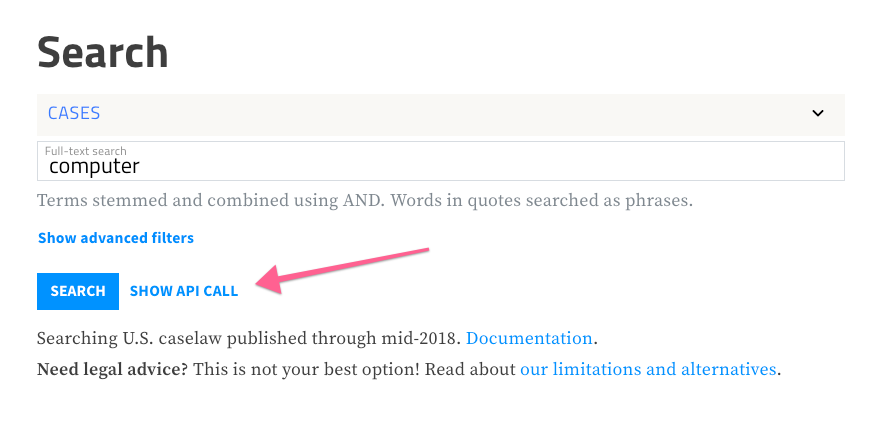
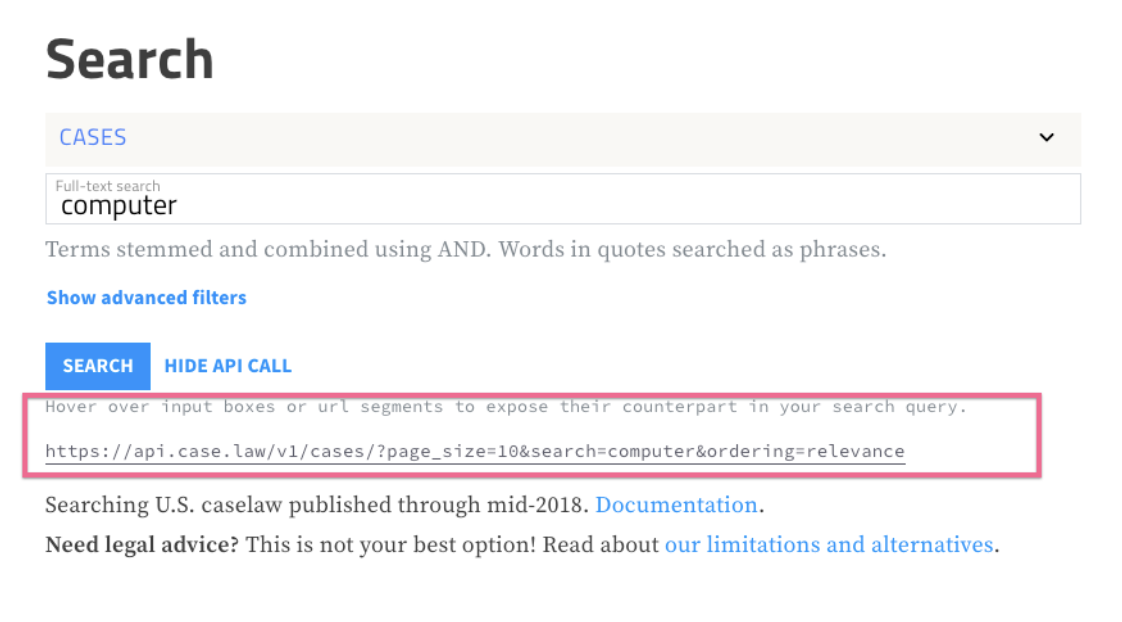
If you put that URL into your browser, you’ll see the search results that are returned by our API. Likewise, when we display a case for reading, we also give you a button to view the case as structured data using our API:
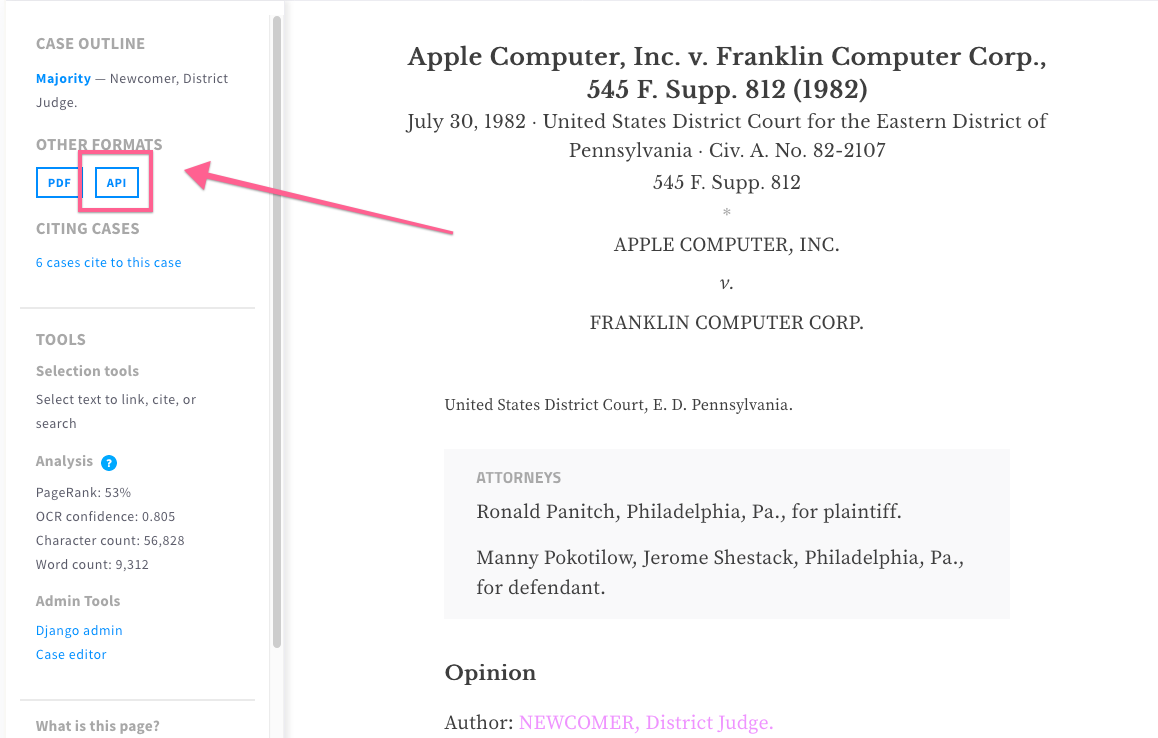
Here’s what that structured data looks like:

We do this to help demystify the tech that powers legal information services, so that we all can demand more of the providers we rely on and so we can experiment in building our own things. Eventually, we expect others will make their own interfaces to the data that we make available through the CAP API. So if you don’t like any of the commercial interfaces, and you don’t like our search interface or case view, we want you to be able to build and experiment with your own. At a minimum, we hope that people will demand more from their information service providers, especially those who charge for access to public information.
Creating Datasets Out of Search Results
A new way we’re connecting human interfaces to court decisions “as data” is to make it easy to download search results as a stand-alone dataset. We’ve heard many requests for this feature from our research community, and we’re excited to announce it today.
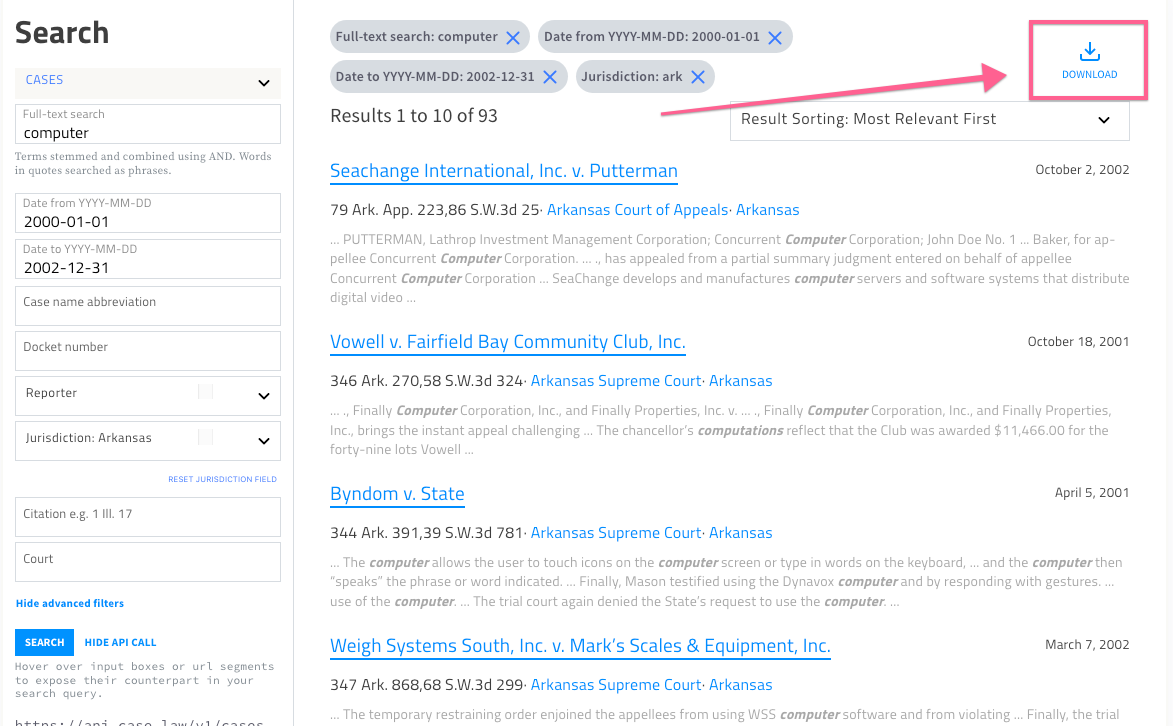
When you click this button, you can download your search results as a custom dataset in JSON or CSV.
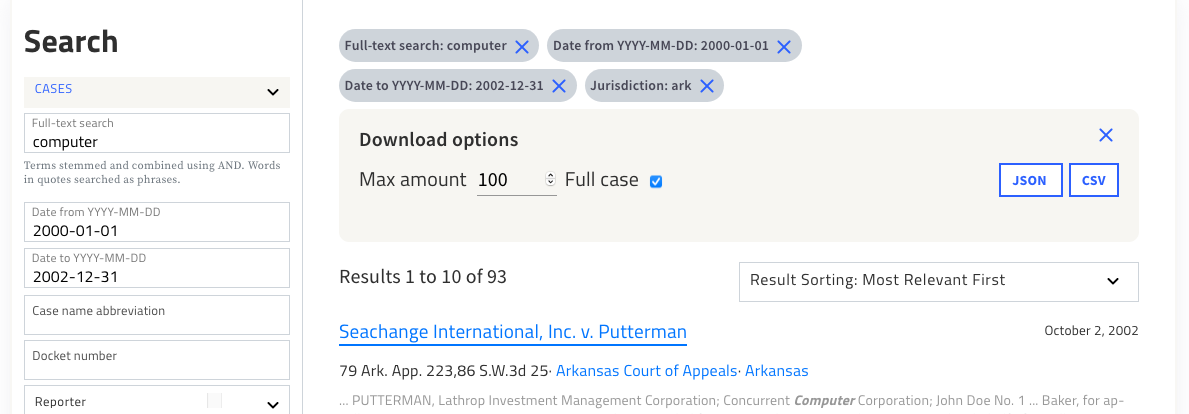
Once you’ve downloaded the dataset, you can work with the cases in your own environment using your own tools and methods. Creating custom datasets is something that most legal information providers do not support at all, which is part of the reason that empirical analysis of law has been so difficult and time-consuming in the past. Law professors and others were forced to spend months (or longer!) compiling collections of cases. We hope to make that process much easier with this feature.
Please let us know how it goes!