Authors:
Kristi Mukk and Clare StantonPublished:
The Perma team has landed back in the US after our trip to the International Internet Preservation Consortium’s Web Archiving Conference. This year the IIPC met in Oslo at the National Library of Norway, and the conference’s theme was “Towards Best Practices.”
This is a gathering each year of colleagues from around the globe who are working in the web archiving space, ranging from institutions responsible for legal deposits, to researchers working with collections, to people who are building the core tools used for web archiving.
Here are some highlights from the conference that we think our community would find particularly relevant:
Opening Keynote - Libraries, Copyright, and Language Models:

Javier de la Rosa of the National Library of Norway presented on the Mímir Project, an initiative examining the value of copyrighted materials (such as books and newspapers) in training Norwegian LLMs. The Mímir Project offers valuable insights into the role of copyrighted corpora in enhancing model performance on tasks such as sentiment analysis, fairness/truthfulness, reading comprehension, translation, and commonsense reasoning. The findings indicated that copyrighted material improved model performance, largely due to the impact of non-fiction content. This project was important both for the library’s understanding of their own rights when it comes to AI model training and to allow them to advise researchers interested in using web archive collections as data.
Using Generative AI to Interrogate the UK Government Web Archive:
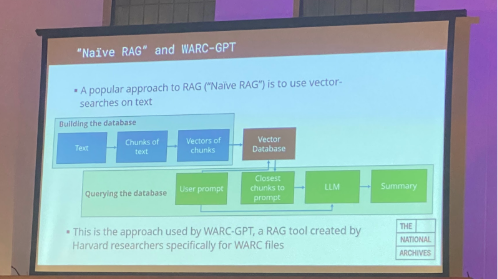
Chris Royds and Tom Storrar of The National Archives (UK) explored the use of Retrieval-Augmented Generation (RAG) to explore the UK Government Web Archive using LIL’s very own WARC-GPT and Microsoft’s GraphRAG. Using their corpus of ~22,000 resources, they explored how RAG might help with the retrieval of lost organizational memory among their departments. One challenge they had to address was the necessity of removing individual records to adhere to their takedown policy. Although their initial findings regarding WARC-GPT’s performance aligned with the results of our case study, it was encouraging to see a real-world application of WARC-GPT performing reasonably well with a significantly larger corpus than in our original study, while also being less computationally expensive than GraphRAG. Overall, they concluded that RAG continues to show promise for exploring WARCs.
UKWA Rebuild: The British Library, which suffered a cyberattack in October 2023, described the challenges they faced in the aftermath and how this affected their discovery services and user access. The UK Web Archive, along with the broader technological infrastructure, systems, policies, and processes of the British Library, had to adapt. Additionally, Gil Hoggarth described their “secure by design” framework in the rebuild process, along with their intention to prioritize a cloud-first approach. Interestingly, it was a recent on-site storage backup that prevented the UKWA from more severe data loss.
Insufficiency of Human-Centric Ethical Guidelines in the Age of AI: Considering Implications of Making Legacy Web Content Openly Accessible: Gaja Zornada of the Computer History Museum Slovenia (Računališki muzej) described the ethical challenges and implications of making legacy web content openly accessible and the impact this may have for an individual’s right to be forgotten. Especially in this AI moment where archival content is no longer consumed solely by human researchers, legacy web content can be reconstructed, resurfaced, and reinterpreted by AI tools without appropriate context or distinction from contemporary sources. If consumed in isolation, this can mislead users, making it essential to clearly label and contextualize legacy content, as the information it contains may be outdated or irrelevant.
Lost, but Preserved - A Web Archiving Perspective on the Ephemeral Web:
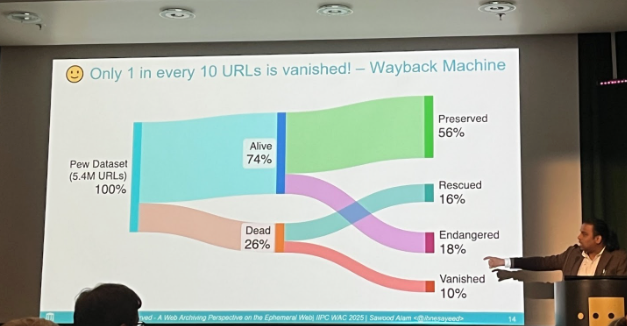
Sawood Alam of the Internet Archive reframed the link rot discourse to be more hopeful rather than alarmist. Recent studies such as the 2024 Pew Research Center study on link rot often highlight the alarming rate of link rot, but fail to highlight the preservation efforts of web archiving institutions and how much of the web has been rescued and resurrected. The Internet Archive’s research discovered that many URLs from these link rot studies have actually been preserved in a web archive. This dynamic brings a finer point to the goals of web archiving: in what situations are we saving the web for future historical knowledge or to maintain the interconnectivity of URLs? This highlights the differences between projects like Perma.cc and collections-based archives. While there is still more work to be done to combat the challenges in preserving the endangered web, web archiving institutions should aim to foster increased awareness and visibility of the efforts of web archives in saving our digital heritage.
What You See No One Saw: Mat Kelly of Drexel University posed the question—”Can we save the web we see from our perspective?”—emphasizing the difference between what an archival crawler captures and what a user actually experiences. Crawlers capture a clean and agnostic version of the web and essentially preserve a “fake web” which is valid but inconsistent with a web user’s perspective. Their team explored how leveraging perspective-based crawling and re-using browser user profiles to archive web advertisements and personalized content can result in capturing a more realistic experience of the web.
From Pages to People: Tailoring Web Archives for Different Use Cases: Andrea Kocsis of the National Library of Scotland and Leontien Talboom of Cambridge University Libraries presented their work on improving the usability of the UK Web Archive by exploring the different audiences for web archives: readers, computational users, and the digitally curious. While web archives are focused on providing access, it is important to answer the question of for whom we are preserving and not make any assumptions about the designated community. They outlined recommendations such as providing datasheets for web archives for computational users, providing a user interface and training to overcome the digital skill gap of the digitally curious, and prefiltering content by topics and themes for readers of web archives to explore so they don’t need to come to the web archives with a research question already in mind. They also highlighted the need to increase awareness of available web archive resources through outreach events such as exhibits and creative approaches that bridge the online and the offline through digital storytelling, data visualization, and art.
As always, spending time with the international community brought together by IIPC was a pleasure and we look forward to next year in Brussels!